
Why do we need to optimize the PDF file size?
The compression involves reducing the original PDF’s content to decrease the total file size. By compressing PDFs, you can often reduce file size by 20% to 30% or more, allowing for easier sharing of large PDFs via email or upload to online without losing quality or readability.
PDF compression is a crucial aspect of development, as it aims to reduce file size without significantly compromising quality. Understanding the structure and components within a PDF is essential for effective compression. Key factors include image resolution (high, medium, or low), which affects zoom levels based on render types (vector or raster), as well as embedded fonts, color profiles, metadata, text content, and the overall structure of the PDF (flat or tree-based).
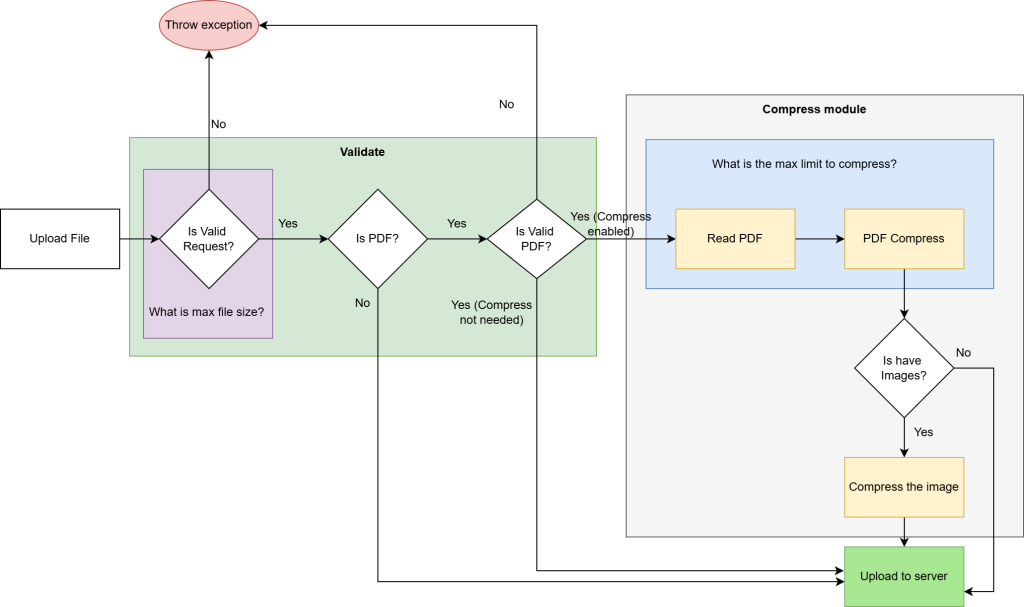
What caught my attention?
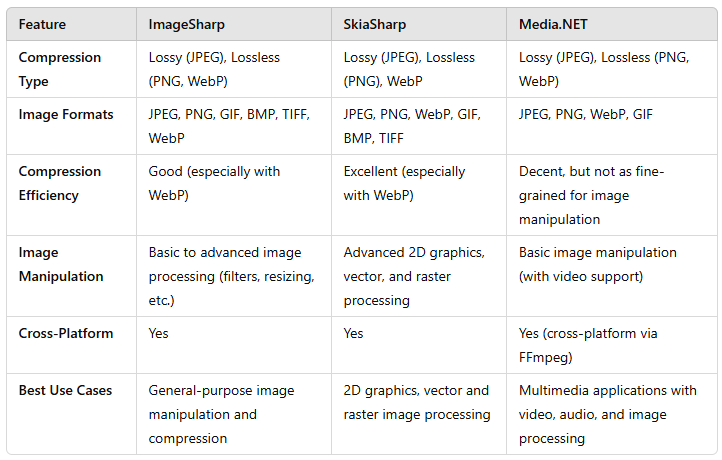
Compression can be achieved through various options, including client-side tools (like jsPDF), backend libraries (such as iText7, PdfSharp, and IronPDF), and server-based tools like Ghostscript. Based on my research, iText7 stands out as a suitable choice, as it effectively compresses files while maintaining a readable structure. However, for further optimization, especially in reducing image resolution (which often consumes the most space), an additional tool would be beneficial. And options are Imagesharp, SkiaSharp and Media.NET . I believe Imagesharp would be the best option to proceed with.
Getting to the point,
iText7 will serve as the component to read the PDF stream and extract the layout structure and objects within the PDF. This allows us to navigate through the content and make any necessary logic changes or adjustments as needed. If there are any image objects ImageSharp will handle rest of the resizing and encoding the images to achieve compression. These optimized images will then be re-integrated into the document layout. Ultimately, we will obtain a reduced file size while maintaining the quality specified in the configuration.
ImageSharp provides various encoders available that allow for quality adjustments, but the most reliable option is the JpegEncoder, as it effectively maintains good quality while also providing size reduction.
For the compression process, either the InMemory or TempFile approach can be used, depending on the scenario. InMemory is ideal for smaller files or simpler tasks, as it operates entirely in RAM, offering fast read and write operations but increasing memory usage under high loads. On the other hand, TempFile is better suited for larger files or high-concurrency scenarios, as it relies on disk I/O to manage data. However, this introduces some latency and requires proper cleanup to delete temporary files after execution to avoid resource clutter.
Do we need to manage the resources?
To manage multiple requests effectively, concurrency control is crucial. Using SemaphoreSlim allows us to limit the number of concurrent operations, ensuring efficient resource usage while maintaining system responsiveness. Regardless of the chosen approach, incorporating error handling and performance monitoring ensures a stable and reliable compression process.
Let’s explore how to create a service to handle the logic.
using iText.Kernel.Pdf.Xobject;
using iText.Kernel.Pdf;
using System.IO;
using System.Threading.Tasks;
using Microsoft.Extensions.Configuration;
using System.Threading;
using iText.IO.Image;
using SixLabors.ImageSharp.Formats.Jpeg;
using SixLabors.ImageSharp.Processing;
using System.Linq;
using System;
using SixLabors.ImageSharp;
namespace TuneTipsNet.Sevices.File.Helper
{
public class OptimizePDFService : IOptimizePDFService
{
private const int MaxConcurrent = 2;
private readonly SemaphoreSlim _semaphore;
public OptimizePDFService()
{
_semaphore = new SemaphoreSlim(MaxConcurrent);
}
public async Task<byte[]> Compress(Stream fileStream, CancellationToken cancellationToken)
{
await _semaphore.WaitAsync(cancellationToken);
try
{
return await ReadWriteFile(fileStream, cancellationToken);
}
finally
{
_semaphore.Release();
}
}
private async Task<byte[]> ReadWriteFile(Stream fileStream, CancellationToken cancellationToken)
{
var tempFilePath = Path.GetTempFileName();
await Task.Run(async () =>
{
using var pdfReader = new PdfReader(fileStream);
using var pdfWriter = new PdfWriter(tempFilePath, new WriterProperties().SetFullCompressionMode(true));
using var pdfDocument = new PdfDocument(pdfReader, pdfWriter);
for (var i = 1; i <= pdfDocument.GetNumberOfPages(); i++)
{
var page = pdfDocument.GetPage(i);
var resources = page.GetResources();
var xObjects = resources.GetResource(PdfName.XObject);
// Check for each XObject if it's an image
if (xObjects != null)
{
foreach (var xObjectName in xObjects.KeySet().ToList())
{
var obj = xObjects.Get(xObjectName);
if (obj is PdfStream stream && PdfName.Image.Equals(stream.GetAsName(PdfName.Subtype)))
{
var imgObject = new PdfImageXObject(stream);
var imgBytes = imgObject.GetImageBytes();
var xObject = xObjects.GetAsStream(xObjectName);
var compressedImage = await CompressImageWithImageSharp(imgObject);
xObjects.Put(xObjectName, compressedImage.GetPdfObject());
}
}
}
}
}, cancellationToken);
using var fs = new FileStream(tempFilePath, FileMode.Open, FileAccess.Read, FileShare.None, 4096, FileOptions.DeleteOnClose);
var readData = new byte[fs.Length];
await fs.ReadAsync(readData, cancellationToken);
return readData;
}
private async Task<PdfImageXObject> CompressImageWithImageSharp(PdfImageXObject imgObject)
{
using var image = Image.Load(imgObject.GetImageBytes());
var (imgW, imgH) = GetResizeImage(image.Width, image.Height);
image.Mutate(x => x.Resize(new ResizeOptions
{
Size = new Size(imgW, imgH),
Mode = ResizeMode.Max
}));
using var ms = new MemoryStream();
var encoder = new JpegEncoder { Quality = 75 }; //Default
await image.SaveAsync(ms, encoder);
ms.Seek(0, SeekOrigin.Begin);
return new PdfImageXObject(ImageDataFactory.Create(ms.ToArray()));
}
private (int, int) GetResizeImage(float imgW, float imgH) //Info: Based on needed customize the ratio
{
var MaxHeight = 800;
if (imgH > MaxHeight && imgH > imgW)
{
var aspectRatio = (float)imgW / imgH;
var newWidth = MaxHeight * aspectRatio;
return ((int)Math.Round(newWidth), MaxHeight);
}
else
{
var customWidth = 768 * ((float)70/ 100); //Info: Based on percentage
return ((int)Math.Round(customWidth), int.MaxValue);
}
}
}
}
That’s it, now you can easily integrate the above service into your application where PDF upload handled and provides flexible configuration options to meet your specific requirements. It ensures optimal performance, scalability, and adaptability, allowing you to streamline operations and enhance the user experience.
I’d love hear any comments or thoughts ?
Comments
Very useful info. Hope we’ll have more ….